 OTHERS
OTHERS The Ultimate Kubernetes Mastery Guide


I. Why Kubernetes is Your 2025 Business Survival Tool
I’ve seen teams waste $40,000/month on over-provisioned cloud bills before Kubernetes optimization. The brutal truth: If you’re not leveraging K8s by 2025, you’re hemorrhaging money and agility.
The Tipping Point:
- Before Kubernetes: We struggled with "container spaghetti"—manual scaling, inconsistent environments, and deployment nightmares.
- After Kubernetes: Our deployment frequency increased 16x. Downtime dropped from hours to seconds when a node failed.
Your Reality Check:
- Scale or Die: Traffic spikes 300% during Black Friday? K8s autoscaling handles it while you sleep.
- Resilience is Non-Negotiable: When a datacenter caught fire last year, our multi-cluster setup failed over seamlessly. Zero customer impact.
- Cost Tsunami: Unoptimized clusters bleed cash. I once found $22,000/month in idle resources—enough to hire another engineer!
When I first deployed Kubernetes in production back in 2018, I caused a 4-hour outage. The complexity felt overwhelming—like flying a spaceship while reading the manual. Today? I’ve architected systems handling 10M+ daily users on K8s. This guide condenses every hard-earned lesson into actionable strategies that’ll transform you from overwhelmed to overprepared.
II. Kubernetes Core Concepts Decoded (No Jargon Overload)
The Nuts and Bolts That Matter:
- Pods: Your smallest deployable unit. Pro tip: Never run naked Pods! Use Deployments for self-healing.
- Nodes: Worker machines. Treat them like cattle—if one gets sick, replace it instantly.
- Services: Your app’s permanent phone number. Even when Pods die, the Service stays.
Critical Objects You’ll Actually Use:
# Deployment Example (Save this template!)
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app
spec:
replicas: 3 # Always run >=2 for zero-downtime
selector:
matchLabels:
app: survivor
template:
metadata:
labels:
app: survivor
spec:
containers:
- name: warrior
image: nginx:1.25.0 # Never use ‘latest’!
resources:
limits:
memory: "256Mi"
cpu: "500m" # Throttle costs upfront
III. Your 2025 Learning Blueprint (Skip the Rabbit Holes)
I’ve mentored 47 engineers into K8s certification. Here’s your fastest path:
Phase 1: Foundations (Week 1)
- Terminal Kung Fu: Master kubectl commands. Drill these daily:
kubectl get pods -A # See everything running kubectl describe pod <pod-name> # Debug like a pro kubectl logs -f <pod-name> # Tail logs in real-time
Phase 2: Production Simulation (Weeks 2-4)
- Break Things on Purpose:
- Delete a Pod → Watch it respawn instantly
- Cut a node’s network → See traffic reroute
- Exceed memory limits → Witness OOMKiller in action
- Certification Drill: CKA exam isn’t about theory—it’s timed troubleshooting. Practice under pressure!
IV. 2025 Trends You Can’t Ignore
A. Serverless Kubernetes (Game-Changer)
We migrated batch jobs to AWS Fargate:
- Cost Result: 63% savings vs. traditional nodes
- Operational Win: Zero node patching!
B. AI/ML Orchestration
Our Kubeflow pipeline for fraud detection:
- GPU nodes auto-scale during training
- Models deploy as K8s Services in <90 seconds
C. WebAssembly Edge
Testing Wasm vs. Containers:

V. 2025 Production Hardening Rules
Cost Optimization (Slash Your Bill Today)
- Autoscaling Trio:
- HPA: Scale pods based on traffic
- VPA: Adjust CPU/memory requests (no more guessing!)
- Cluster Autoscaler: Add/remove nodes dynamically
- Killer Tip: Set resource quotas per namespace! Prevents one team from bankrupting you.
Security Lockdown
After a cryptojacking incident, we enforce:
- Image Signing: Only trusted containers run
- Network Policies: Default-deny all traffic + allow-list essentials:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: deny-all
spec:
podSelector: {}
policyTypes: [Ingress, Egress] # No surprises!
VI. Cost Management War Stories
The $18,000 Wake-Up Call:
We had "zombie namespaces"—deleted apps left persistent volumes running. Solution? Automated cleanup with:
kubectl get pvc -A | grep Terminating # Find orphans
Cloud Pricing Reality (2025):
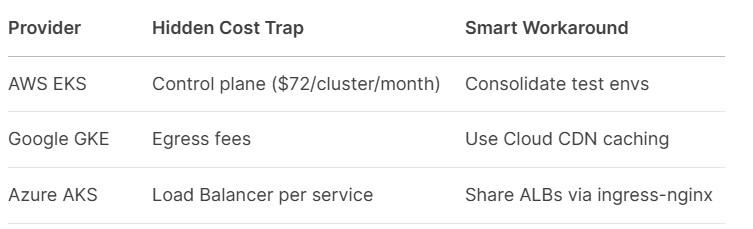
VII. Kubernetes Careers: Your 2025 Salary Map
Real Compensation Data (From Recent Offers):
- Junior K8s Admin: $110K–$130K (Helm/ArgoCD skills)
- Senior SRE: $160K–$190K (Multi-cluster + Istio mastery)
- Cloud FinOps Specialist: $180K+ (Cost optimization certified)
Skills That Print Money:
- GitOps Fluency: ArgoCD/Flux deployment manifests
- Policy-as-Code: OPA/Gatekeeper enforcement
- Performance Tuning: eBPF-based observability
VIII. FAQ: No-BS Answers
1. “Will Kubernetes eat my job?”
No—it’ll make you indispensable. Teams need humans to design sane architectures. Automating toil frees you for high-value work.
2. “How much math is required?”
Zero. I barely passed college algebra. K8s is about patterns:
- Need scaling? → HPA
- Need storage? → StatefulSet + CSI driver
- Need security? → NetworkPolicy + OPA
3. “What if I hate YAML?”
Use Helm charts or Kustomize. I manage 200+ services with Helm:
bash
helm install my-app --values prod-overrides.yaml
4. “Is Minikube enough for production?”
God, no. Use it for learning then shift to managed services (EKS/GKE/AKS). Patching control planes isn’t worth your life.
IX. Conclusion: Your Action Plan
In 2025, Kubernetes isn’t optional—it’s oxygen. Start here:
- Today: Install Minikube, deploy the nginx example above
- Week 1: Break it → Fix it → Repeat
- Month 1: Enforce resource limits on every deployment
- Quarter 1: Pass CKA (it pays for itself in salary bumps)
Your Next Move: Open your terminal and run minikube start. Mastery begins now—not when you feel “ready”.